
Alek Safar, creator of AI benchmarks and serial entrepreneur, has launched ClockBench, a visual benchmark test focused on evaluating AI’s ability to “read” analog clocks. The results are striking: humans achieved an average accuracy rate of 89.1%, whereas the top-performing model among the 11 leading mainstream large models tested scored a mere 13.3%. In terms of difficulty, this benchmark is on par with the “AGI Final Test (ARC-AGI-2)” and more challenging than “Humanity’s Last Exam“.
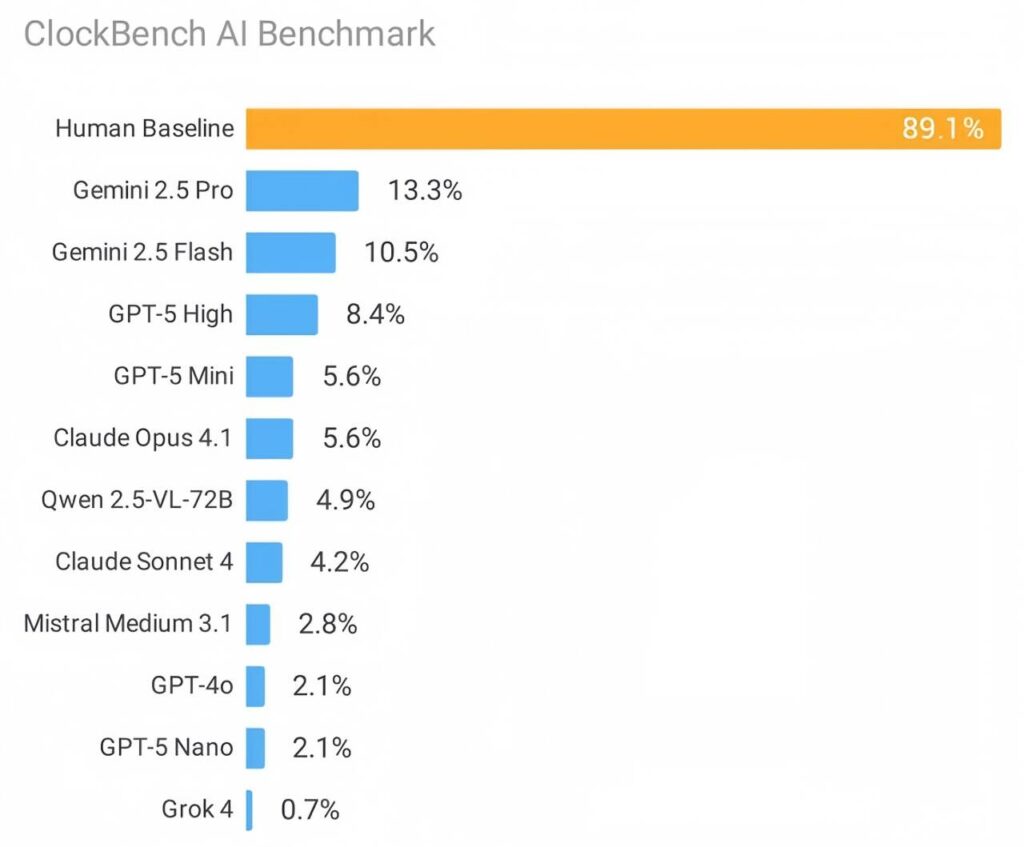
ClockBench comprises 180 clocks and 720 questions, laying bare the limitations of current cutting-edge large language models (LLMs). Although these models have demonstrated impressive reasoning, mathematical, and visual comprehension capabilities across multiple benchmarks, such capabilities have not been effectively transferred to the task of “reading clocks”. Potential reasons include the training data lacks sufficient memorable clock features and time combinations, forcing models to infer mappings between clock hands, hour marks, and time readings. The visual structure of clocks cannot be fully mapped to the text space, restricting text-based reasoning.
There is, however, a silver lining: despite their limitations, the top-performing models have shown preliminary visual reasoning abilities. Their time-reading accuracy and median error are significantly better than random results. Further research is needed to determine whether these capabilities can be enhanced through scaling up existing paradigms (data volume, model size, computing resources, and reasoning budgets) or if entirely new approaches are required.
How Does ClockBench Challenge AIs?
Over the past few years, LLMs have made remarkable progress across various fields, with cutting-edge models quickly reaching “saturation” on many popular benchmarks. Even the latest benchmarks, specifically designed to assess both “expertise and advanced reasoning”, have seen rapid breakthroughs.
A typical example is Humanity’s Last Exam, OpenAI’s GPT-4o scored only 2.7% on this benchmark. xAI’s Grok 4 improved the score to 25.4%.With optimizations like tool utilization, scores can even reach the 40%–50% range.
Nevertheless, we still observe that AIs underperform in certain tasks that are trivial for humans. This has led to the development of benchmarks such as SimpleBench and ARC-AGI, which are specifically designed to be “easy for ordinary people but difficult for LLMs”. ClockBench draws inspiration from this “human-easy, AI-hard” philosophy.
The research team noted that reading analog clocks is equally challenging for both reasoning-based and non-reasoning-based models. As a result, ClockBench has built a robust dataset that demands high levels of visual precision and reasoning ability.
What Does ClockBench Include?
ClockBench Includes 36 newly designed custom clock faces, with 5 sample clocks generated for each face, a total of 180 clocks, each paired with 4 questions, amounting to 720 test questions and 11 vision-capable models from 6 laboratories were tested, and 5 human participants were recruited for comparison.

When the time on a clock is legible, LLMs are required to break down the information into components and output it in JSON format, including Hours, Minutes, Seconds, Date, Month, and Day of the week—all of which must be included if the clock face contains such information. Additional tasks include time addition and subtraction, rotating clock hands, and time zone conversion.
The Results Are Unexpected
The gap in accuracy between models and humans is not only enormous but also characterized by distinct error patterns. The median error for humans is a mere 3 minutes, while that of the top-performing model is as high as 1 hour; weaker models even have a median error of approximately 3 hours.
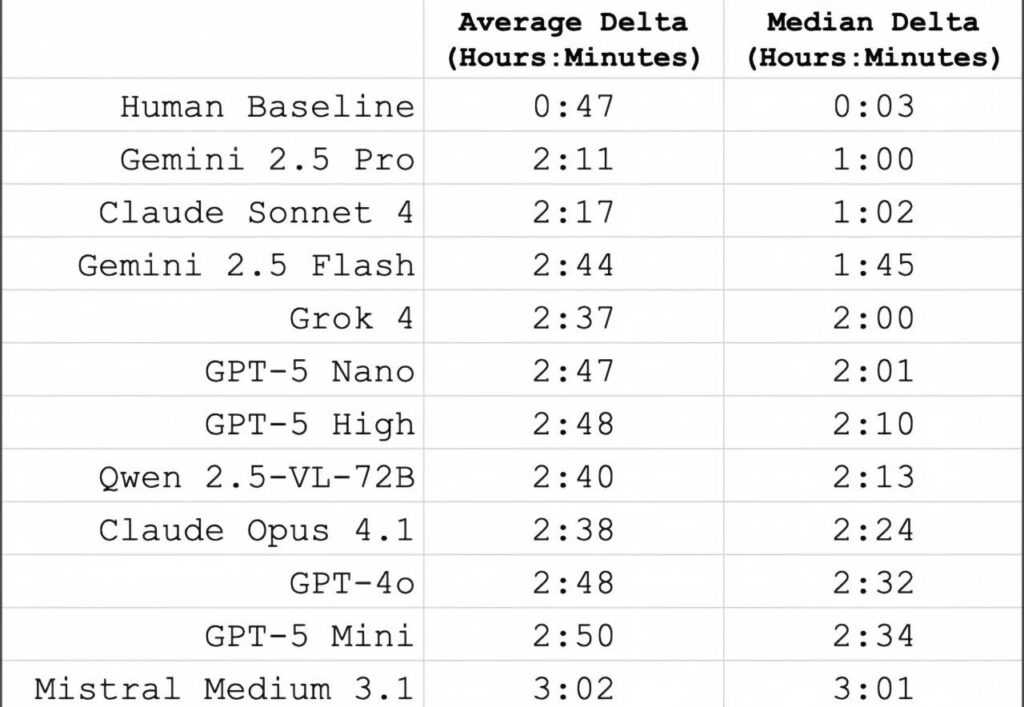
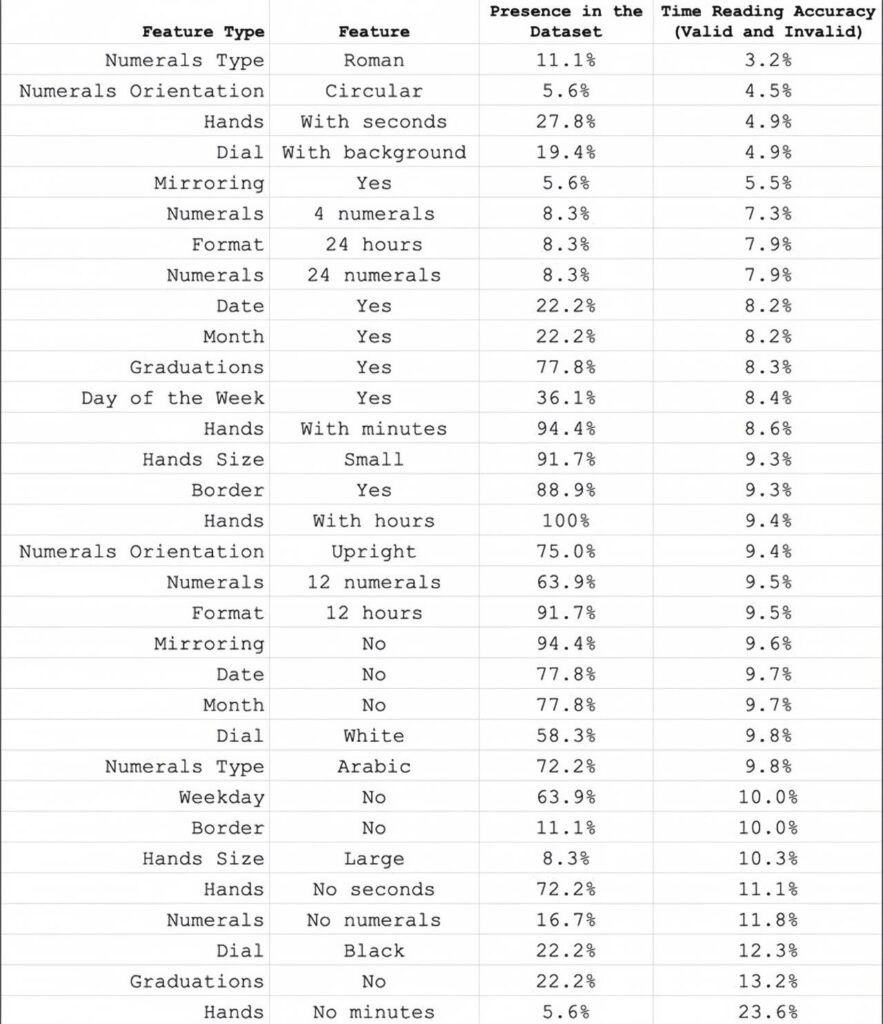
Another interesting finding is that the difficulty of reading certain clock features varies significantly. Models perform worst when reading uncommon complex clocks and in scenarios requiring high precision. The orientation of Roman numerals and circular numerals is the hardest to identify, followed by second hands, cluttered backgrounds, and mirrored clocks.
Interestingly, tasks other than time-reading prove relatively easier for models. The top-performing model can accurately answer questions about time addition and subtraction, clock hand rotation angles, or time zone conversion, with an accuracy rate of up to 100% for some questions.In the original dataset, 37 out of the 180 clocks display “invalid times”. Both humans and models achieve a higher success rate in identifying these “invalid times”.
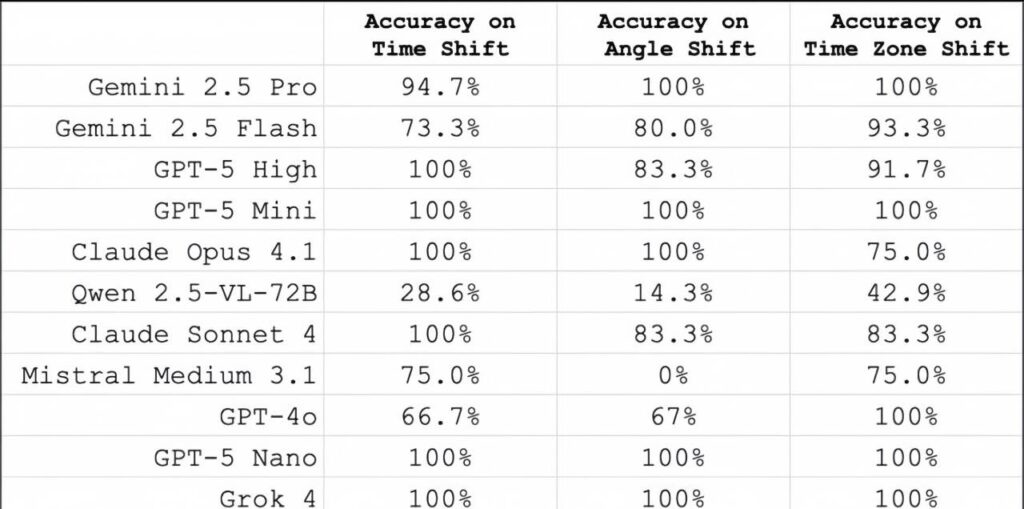
When comparing the performance of different models, a general trend emerges: larger reasoning-based models generally outperform smaller models or non-reasoning-based ones.


{kind=link}