
A revolutionary breakthrough in the field of artificial intelligence is quietly changing the landscape of video generation. According to the latest news, a joint research team from Stanford University, ByteDance’s Seed Lab, Johns Hopkins University, and The Chinese University of Hong Kong recently published a significant achievement in a prestigious computer graphics journal, bringing an unprecedented leap forward for AI video generation technology.
The core of this research lies in solving a long-standing problem plaguing AI video generation: how to maintain information coherence and integrity while processing ultra-long videos, all without incurring an explosive growth in computational load. Traditional AI video generation systems, akin to a person with short-term memory impairment, struggle to maintain content coherence over extended periods, often resulting in videos with disjointed plots and abrupt character changes. The “Mixture of Contexts” (MoC) technology proposed in this study equips AI video generation systems with an intelligent “memory engine.”

The innovation of MoC technology lies in its reframing of the video generation process as an information retrieval problem. Imagine needing to find specific information in a vast library; the traditional method requires remembering the detailed content of every book, which is clearly impractical. MoC technology, however, acts like an efficient librarian, quickly locating the most relevant section of books based on current needs, thereby significantly saving time and effort.
Using MoC technology, the research team achieved dual improvements in video generation efficiency and quality. In experiments, videos generated with MoC showed significant enhancements in character identity consistency, motion coherence, and scene coordination. Simultaneously, computational efficiency increased by 7 times, and the actual generation speed accelerated by 2.2 times. This means that long videos which previously took hours to generate can now be produced with high quality in a fraction of the time.
The challenge of long-form video generation stems from the exponential increase in information that needs to be processed as video length grows. Traditional methods, like the self-attention mechanism, require processing every detail of every frame in the video and understanding the relationships between them. However, this approach is computationally expensive and struggles to maintain long-term memory coherence. MoC technology solves this problem by intelligently selecting and processing the most relevant chunks of information.
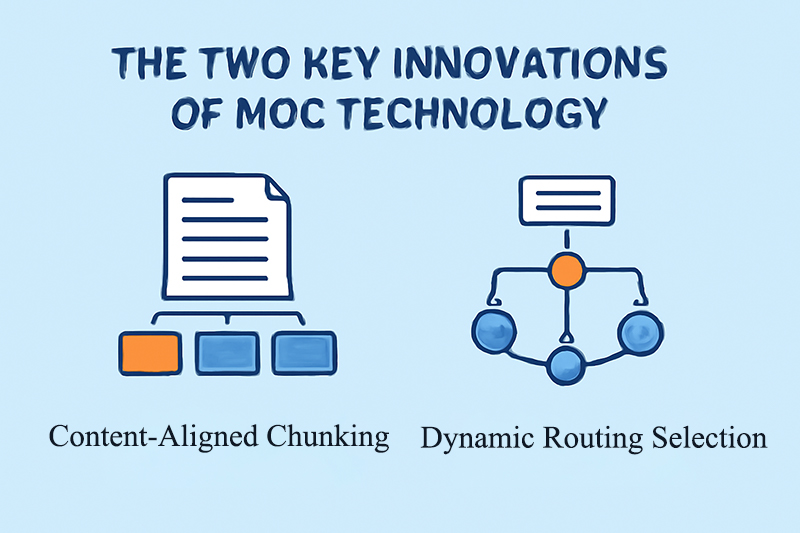
The two key innovations of MoC technology are “Content-Aligned Chunking” and “Dynamic Routing Selection.” Content-Aligned Chunking divides information into relatively complete and consistent content chunks based on natural video boundaries, such as shot changes and scene transitions. Dynamic Routing Selection then quickly identifies the most relevant few information chunks for detailed analysis based on relevance scores between the content currently needing generation and historical information chunks. This method not only improves computational efficiency but also ensures the coherence and consistency of the generated video.
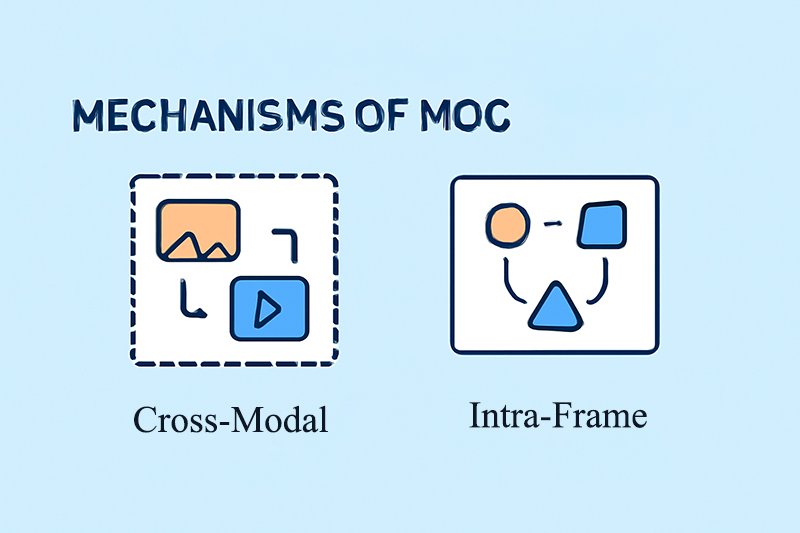
MoC technology also introduces “Cross-Modal Connectivity” and “Intra-Frame Connectivity” mechanisms, ensuring the video generation process can access text description information and maintain coherence between frames within the same shot. Furthermore, a “Causality Constraint” mechanism ensures information can only flow from the past to the future, preventing loop closure issues and enabling the system to continuously produce novel and coherent content.
In terms of technical implementation, the research team faced significant engineering challenges. Through innovations in memory management, computational efficiency optimization, and system architecture design, they successfully transformed MoC technology into a practically usable system. Particularly in handling multi-modal information fusion, the team designed a unified information representation framework, allowing the system to seamlessly compare and integrate information from different modalities.
Experimental validation showed that MoC technology outperforms traditional methods across multiple evaluation metrics. In single-shot short video tests, MoC excelled in subject consistency, background consistency, and motion quality. In long-form video generation tests, MoC achieved 85% information sparsification, reduced the total computational load by over 7 times, increased actual generation speed by 2.2 times, while maintaining video quality comparable to or even higher than traditional methods.
The success of MoC technology not only marks a significant turning point in the field of AI video generation but also has broad implications for practical applications. Educational content creators, corporate communication departments, and individual creators will all benefit from this technology, enabling easier production of high-quality long-form video content. MoC technology could also be applied to other AI tasks requiring long-term memory and coherence, such as game AI, robot control, and virtual assistants.
As MoC technology continues to develop and improve, we have reason to believe that a brand new content creation ecosystem is incubating. In the future, more people will have the opportunity to transform their stories, ideas, and dreams into vivid video content, further promoting the democratization and diversification of media creation.


{kind=link}