
A pivotal advancement is reshaping the capabilities of large language models (LLMs), addressing a critical bottleneck that has long limited their real-world utility: lackluster logical reasoning. A joint research team spanning Peking University, Tsinghua University, the University of Amsterdam, Carnegie Mellon University (CMU), and the Mohamed bin Zayed University of Artificial Intelligence (MBZUAI) has released a comprehensive survey that categorizes LLMs’ logical flaws, proposes targeted solutions, and charts a path for future innovation.

The findings, published as a preprint on arXiv and accepted to the 2025 International Joint Conference on Artificial Intelligence (IJCAI) — a top-tier venue with a mere 19.6% acceptance rate for its Survey & Tutorial track — offer a roadmap to make AI more consistent, reliable, and fit for high-stakes tasks like medical diagnosis and legal analysis. Fengxiang Cheng, a PhD candidate at the University of Amsterdam (and former master’s student of Tsinghua’s Professor Fenrong Liu), leads the work as first author, with Peking University Assistant Professor Haoxuan Li serving as corresponding author.
The Core Challenge: Logical Inconsistency
While LLMs excel at natural language processing, they often falter in rigorous logical reasoning — a gap that undermines their value in scenarios requiring precision, from operational management to decision-making. The most glaring issue is logical inconsistency: models may produce contradictory outputs even when answering related questions.
A classic example involves the Macaw QA model: When asked “Is a magpie a bird?”, it correctly responds “Yes”; when queried “Do birds have wings?”, it answers “Yes”; yet when pressed “Does a magpie have wings?”, it contradicts itself with “No”. “LLMs are trained on vast amounts of text, much of which contains subjective opinions rather than objective facts — this leads to what we call ‘negation consistency’ problems,” Li explains to DeepTech.
To systematically address this, the team’s survey categorizes LLMs’ logical challenges into two overarching areas:
1.Logical Question Answering: Struggles with complex reasoning tasks, such as evaluating conclusions based on hundreds of premises across deductive, inductive, or abductive reasoning modes.
2.Logical Consistency: Failures to maintain coherence across related queries, encompassing four key subcategories:
Implication consistency: Difficulty processing “if P, then Q” conditional logic.
Transitivity consistency: Inability to follow chains like “P→Q→R” (e.g., failing to infer “A→C” from “A→B” and “B→C”).
Fact consistency: Errors when applying LLMs to vertical fields (e.g., medicine) that require aligning outputs with domain-specific knowledge bases.
Compositional consistency: Inability to balance multiple consistency requirements simultaneously.
“These logical rules are well-established in linguistics and reasoning, but LLMs rarely adhere to them in practice,” notes Professor Liu of Tsinghua’s Department of Philosophy. “Our systematic classification lays the groundwork for both theoretical progress and methodological innovation in the field.”
Bridging the Gap: Symbolic Logic Meets Natural Language
A fundamental hurdle in enhancing LLMs’ reasoning lies in a mismatch between training data and logical reasoning itself: LLMs learn from natural language text, but logic relies on symbolic language (formal rules and symbols). This disconnect means LLMs often rely on surface-level pattern matching rather than true logical understanding.
Li, whose research focuses on causal reasoning, illustrates the problem: “On a hot summer day, ice cream sales and crime rates both rise — but an LLM might incorrectly infer a causal link between them. Similarly, while an LLM may learn ‘A→B’ and ‘B→C’ separately, it often can’t deduce ‘A→C’ on its own, even though this is a basic rule of transitivity in logic.”
To overcome this, the team proposes two complementary strategies:
Data Augmentation: Convert symbolic logical relationships (e.g., “A→C”) into natural language text and add them to LLM training datasets.
Capability Enhancement: Train LLMs to independently derive new logical conclusions from existing knowledge, rather than just memorizing patterns.
“Logic has evolved over 2,000 years into a rigorous system of rules that guarantee valid conclusions from premises,” Liu says. “Integrating these time-tested rules with LLMs holds great promise for boosting their reasoning ability — even when training data is scarce.”
A Hybrid Solution: Merging AI and Automated Theorem Provers
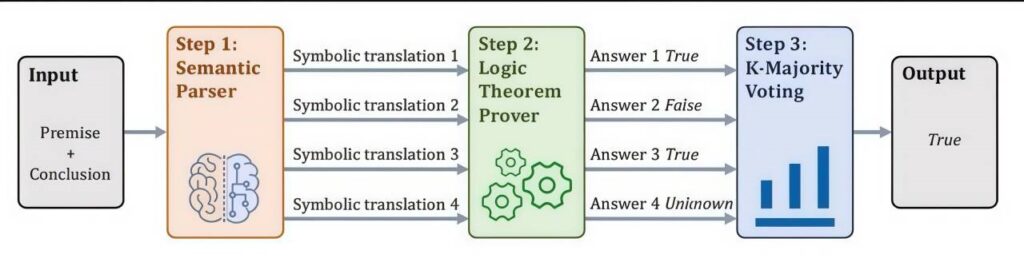
The team’s most innovative contribution is a hybrid reasoning framework that combines LLMs’ strength in natural language with the precision of automated theorem provers (tools that formally verify logical arguments). Here’s how it works:
1.A semantic parser converts natural language questions and premises into formal symbolic logic.
2.An automated theorem prover uses these symbols to perform rigorous logical deductions.
3.The results are translated back into natural language, with a “K-Majority Voting” mechanism resolving inconsistencies if multiple symbolic translations exist (e.g., trusting the theorem prover’s output when translations align, and using majority votes to resolve ambiguities).
This approach leverages the best of both worlds: the theorem prover ensures strict logical validity, while the LLM handles natural language understanding and generation. Early tests show the hybrid framework significantly improves LLMs’ performance on complex logical tasks.
Crucially, the team balanced efficacy with efficiency — a key concern in AI development. “We drew on dual strengths: AI experts optimized model fine-tuning for efficiency, while our team specialized in converting between natural and logical language to boost reasoning without overcomplicating the model,” Li explains.
Implications for Trustworthy AI
IJCAI reviewers praised the research for its “deep insights” and noted that enhancing LLM logical reasoning is a “highly relevant and important area” for AI advancement. Beyond improving LLMs themselves, the work paves the way for trustworthy AI systems — critical for applications like medical diagnosis (where logical consistency can mean life or death) and legal reasoning (where contradictory outputs could undermine justice).
As the team continues to refine its hybrid framework and expand its data augmentation strategies, the vision of AI that “thinks logically” moves closer to reality. For content creators, businesses, and researchers alike, this latest trend promises LLMs that are not just fluent, but reliable — turning AI from a tool for generating text into a partner for making sound, logical decisions.


{kind=link}